When changing the implementation of a time clock, I had to switch from a static method — think about a classic call to clock_gettime() for example — to a per-thread model. Long story short, it was about a constant TSC that was not so constant across different sockets.
Per-thread and static variables: that sounds like a perfect case for Thread-Local Storage (TLS). However this time clock was widely used in my project and was taking so far a couple of CPU cycles, and I wanted to be sure that the TLS would not add a significant overhead.
A quick look on Google only revealed an article from the Intel Developer Zone: the hidden performance cost of accessing thread-local variables. Among pro-tips like “you simply have to buy a Intel©® VTune™ licence and don’t forget the Parallel Studio XE©®™ it only costs 2k$”, the awesome screenshots or the comment section where someone says that the code is slow due to the TLS implementation of Windows while another one points out the code was running under Linux, I simply decided to figure out myself.
So I did what I prefer: I profiled it.
TL;DR
If you have statically linked code, you can use a thread local variable like another one: there is only one TLS block and its entire data is known at link-time, which allows the pre-calculation of all offsets.
If you are using dynamic modules, there will be a lookup each time you access the thread local variable, but you have some options in order to avoid it in speed-critical code.
µ-benchmarking the access of TLS data
I wrote a snippet that mimics the code I had in production: one was accessing a static variable, the other one a thread local variable, through a static method of the class.
Note that the thread_local keyword was introduced in C++11, and implemented in GCC 4.8 or newer. If you are using an older version, you can use the __thread GCC keyword.
To time my experiments, I am using geiger, a benchmarking library I developed. geiger can read hardware performance counters — using the PAPI library — and is ideal to benchmark very short snippets of code.
Here, I simply declare a benchmark suite with two tests. The first one accesses static data, and the second one thread local data. The suite is run twice: the first time, each test is run once, and the second time, each test is run one hundred times.
Let’s build it with our favorite flags:
The results are quite straightforward: no overhead at all. There is always a bit of jitter with hardware counters, so do not
conclude we have more cycles with the TLS test, there is quite some variance here between several runs.
The assembly code also confirms it. I build with CLang 3.6 but I got the same with GCC 4.7:
NB: the glibc is using the segment register FS for accessing the TLS
How about __tls_get_addr ?
Apparently, all is good, I can use TLS as I want. But hang on… how about this function that was in the callstack on the Intel blog, __tls_get_addr ?
One thing that always scares me the most when I do micro benchmarks is about the reliability of their results. Indeed, it is very easy to screw up. You have to generate some realistic inputs that will trigger the same behavior that you got in production, without too many side effects. And from the D-cache to the BTB, everything is hot…
Here, we have a sneaky case: the compilation is part of the environment of our benchmark. If the thread variable is in a dynamic module, the linker cannot compute a direct reference to it and we get the much vaunted lookup!
Let’s build it again, as a shared library this time:
There is in this case a difference ; the method that accesses the thread local variable takes twice more time. Please not that
this overhead is still very small, as in this case we compare it to an extremely cheap operation…
The assembly code shows the same difference:
The TLS implementation in ELF
As global and static variables are stored in .data and .bss sections, thread local variables get stored in equivalent .tdata and .tbss sections.
Each thread has its on TCB — Thread Control Block — that contains some metadata about the thread itself. One metadata is the address of the DTV — Dynamic Thread Vector — which is a vector that contains pointers to thread local variables and other TLS blocks.
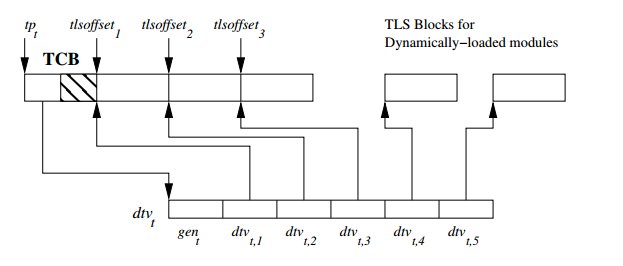
When using statically linked code, everything is simpler as there is only one TLS block. As the offsets to the thread local variables are known at link-time, the compiler is able to generate a direct access to the thread local variable.
But when you have dynamic modules, several TLS blocks are present. It is easier to see with the following simplified version of __tls_get_addr. offset is known at build time, then module_id is the only variable, which is zero when using static linking.
This is the actual implementation from the glibc 2.20:
The ABI specific parts are implemented in sysdeps ; as for x86_64, we access the TCB from the segment register FS:
So what?
Accessing thread local variables is cheap in both cases ; the lookup done by the glibc is very fast (and takes a constant time). But if your code is — or could be — loaded as a dynamic module and is speed-critical, then it can be worth spending some time to avoid this lookup.
One easy win could be to access the thread local data from the same block of code. The compiler will be smart enough to call only once __tls_get_addr. This could be done by, for example, inlining the function that access the TLS.
One could think about keeping the reference of the thread local variable, but I found this solution very dodgy. You might have to prepare your arguments to pass the code review :) …
More information about the TLS and its implementation on GNU/Linux in ELF Handling for TLS from Ulrich Drepper.