Although Boost.MultiIndex is a pretty old library — introduced in Boost 1.32, released in 2004 — I found it rather unsung and underestimated across the C++ community in comparison to other non-standard containers.
In this article, split into multiple parts, I will highlight all the benefits you can get using boost::multi_index_container instead of the standard containers: faster, cleaner and simpler code.
Multiple views
You have a set of struct composed by two integers x and y and do mainly two operations on it:
- adding an entry
- iterating over the set in ascending order on x
- iterating over the set in ascending order on y
This is achievable quite easily with boost::multi_index_container:
The “hard” part done, the usage of the container itself is trivial. Actually, most of the operations are identical to the ones you can find on a standard container. The only
difference is that you have to get a view on the container for some of the operations:
The unfortunate alternative
The alternative and unfortunately most common way to solve this problem is to maintain two std::set, one using a comparator on x, the other one on y. However, there are few problems with this approach:
- it is error prone: each operation has to be done on the two sets, and if you forget you will have a bad time
- the time efficiency is worse on insertion as you have the value twice — and even if the object is small it will be slower due to the memory allocations of the container
- the spatial efficiency will be worse
- it can be complicated if instead of storing twice the value you decide to store a pointer, reference or iterator in one of the two containers: they can be invalidated depending on the container and the operations performed on it
- it is not very elegant from the code perspective
- if the constructor can throw, it will be even more fun, as you will have to handle exceptions properly and erase the previously inserted values
To sum up, yes, you can isolate the two containers in a separate class, wrap all the methods, deal with the exceptions to rollback the operation if something throws and code the unit tests. Good luck, though! And it will be slower than Boost.MultiIndex, and there will be another few hundreds of lines of code to maintain.
Performance
When we do C++, performance usually matters: how fast is this double-indexed boost::multi_index_container compared to the two std::set?
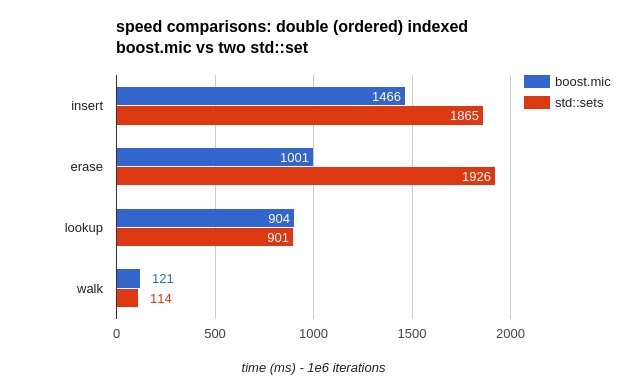
As we thought, the multi_index_container is much faster on insertion (and removal). The solution using two std::set’s forces us to duplicate all the operations that modify the container: on insertion and deletion, both sets need to be updated. This is especially bad as these operations involve memory allocations ; you can then expect this time difference to increase with the size of the value stored.
When doing a lookup or walking in ascending or descending order, performance are almost the same — as they are done only on one std::set and not the two.
The entire code of this benchmark is available on my github
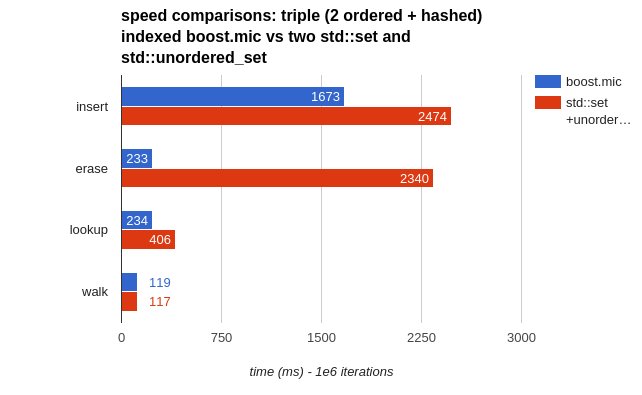
We see that the lookup is slightly slower, probably due to the overhead added by the multiple indexes. What can we do about that? Well, adding a third index, not ordered this time, but hashed!
… and the lookup is now ~5times faster. What is almost free with Boost.MultiIndex — adding an index — has definitely a cost in our alternative solution: if we add a std::unorered_set,
the time of insertion and removal grows significantly (and the complexity of the code that manages this additional container too).
Implementation
Behind the scene, boost::multi_index_container uses a system of headers in order to do its job. Each node consists in the stored object, plus a sequence of headers, depending on the indexes that are used.
There is a specific header for each index type.
Ordered
The ordered index is implemented as a red-black tree, thus the header is composed by 3 pointers: one to the parent and the two children pointers. An interesting point here is that the color of the node is — on most platforms — encoded in the LSB of the parent pointer, resulting in a header of 24 bytes instead of 32 bytes (on a 64-bit systems).
As none of the std::map implementations I checked — libc++ and libstdc++ trunk (at the time of writing…) — performs such space optimization, this might explain the result we got in the previous benchmark, where the lookup was faster on boost::multi_index_container than std::set. I actually don’t know why they don’t perform such optimization, if anybody knows, don’t hesitate to post a comment!
Unordered
The implementation of the hash map requires two pointers for the bucket management.
Again, std::unordered_map (with GCC 6.2 on Linux x86-64) takes more space (3 pointers), which can explain why the lookup was ~20% slower. I didn’t dig into the code of std::unordered_map, I only profiled its memory allocations.
Sequenced
The sequenced index is implemented as a double-linked list: the header is composed by 2 pointers, one pointing to the next node, the other one to the previous node.
Random access
The random access index is implemented with an array of pointers to the nodes. In the node itself, the header is only composed by one pointer, which points back to its corresponding element in the main array of pointers.
Summary
| index type | associated header | size on 64-bit systems |
|---|---|---|
| ordered | 3 pointers | 24 bytes |
| unordered (hashed) | 2 pointers | 16 bytes |
| sequenced | 2 pointers | 16 bytes |
| random | 1 pointer | 8 bytes |
Then, in the previous double-ordered and hashed container, the overhead was 24+24+16=64 bytes. If we take sizeof(int) == 4 bytes, each node takes 72 bytes in memory.
In the other solution, each instance of std::set and std::unordered_set uses 40 bytes (GCC 6.2, Linux, x86-64), resulting in a usage of 120 bytes per node.
That’s all for now! In a second part I will explain why Boost.MultiIndex can help you even if you don’t use multiple indexes.